Następnym zadaniem w CTFie Honeynet Collapse było zadanie 4. Polegało ono na analizie śladów włamania na Windowsie.
Pytanie 1. — data dostępu przez RDP
Poziom trudności: łatwy 🟢
Liczba punktów: 30
Treść: Kiedy atakujący zalogował się do serwera za pomocą protokołu RDP?
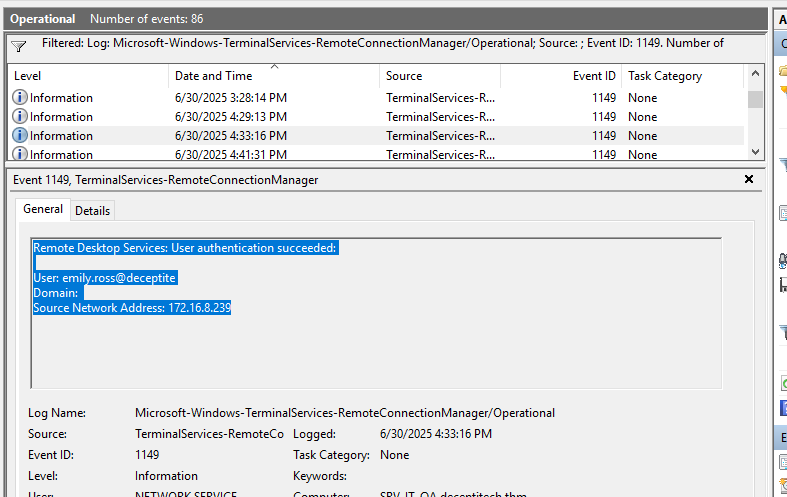
Pierwsze pytanie polegało na znalezieniu daty i czasu logowania atakującego przez protokół RDP. Zacząłem od przeszukiwania logów zdarzeń z kategorii odpowiadającej RDP, korzystając z opisu zadania, który mówił, że połączenie przychodziło z adresu 172.16.8.239.
Zacząłem od przeszukiwania logów z TerminalServices-RemoteConnectionManager, wybierając jedynie zdarzenia o ID 1149 (pomyślne uwierzytelnienie w usłudze Zdalnego Pulpitu), znalazłem połączenie przychodzące z wcześniej wspomnianego adresu IP:
Odpowiedzią na pytanie była data i czas zdarzenia.
Pytanie 2. — podmieniony plik
Poziom trudności: łatwy 🟢
Liczba punktów: 30
Treść: Jaka jest pełna ścieżka do pliku binarnego zastąpionego w celu eskalacji uprawnień?
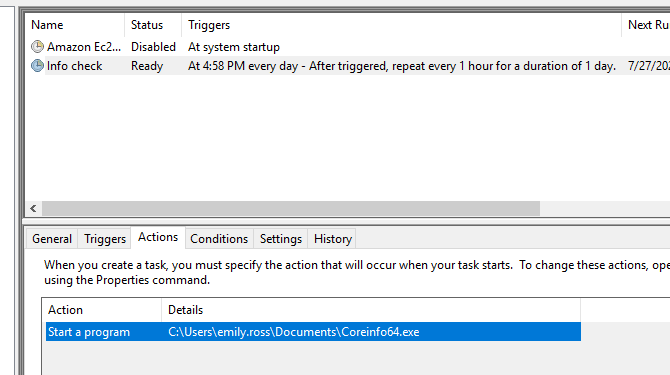
Z opisu zadania można było się dowiedzieć, że administratorka serwera zautomatyzowała okresowe sprawdzanie statusu systemu. Pierwsze co przyszło mi na myśl to sprawdzenie, czy atakujący nie podmienił plików służących temu zadaniu. Domyśliłem się, że stworzyła ona zadanie w harmonogramie zadań (taskschd.msc) — i tak właśnie było:
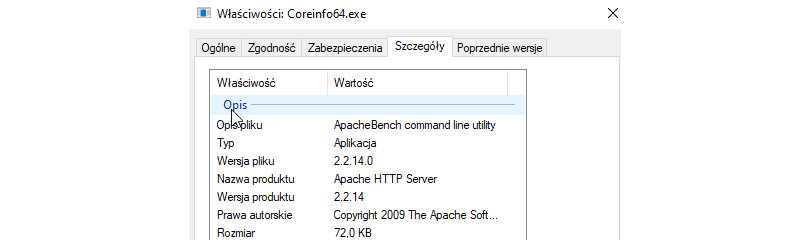
Wyświetlając szczegóły pliku od razu widać, że coś jest nie tak. Opis programu nie zgadza się z oczekiwanym. Czemu Coreinfo jest opisany jako serwer Apache? Tyle mi wystarczyło żeby wiedzieć, że to jest plik, który podmienił atakujący.
Pytanie 3. — co to za plik?
Poziom trudności: średni 🟡
Liczba punktów: 60
Treść: Jakiego rodzaju złośliwe oprogramowanie zawiera zastąpiony plik binarny?
Znaleźliśmy który to plik, ale pozostaje jeszcze się dowiedzieć, co on tak właściwie robi. To pytanie, rozwiązałem za pomocą VirusTotala. Wrzuciłem plik i od razu rzuciła mi się w oczy nazwa Meterpreter. Jest to wyjątkowo znany payload który daje szerokie możliwości interakcji z zainfekowanym systemem i pochodzi z frameworku Metasploit .
Odpowiedzią na pytanie była nazwa tego payloadu.
Odpowiedź dało się również znaleźć w logach PowerShella, znajdujących się w katalogu konta Administrator, ale do nich jeszcze przejdziemy.
Pytanie 4. — kradzież poświadczeń
Poziom trudności: średni 🟡
Liczba punktów: 60
Treść: Jakie pełne polecenie zostało użyte do zrzutu poświadczeń z systemu operacyjnego?
Po eskalacji uprawnień atakujący skradł poświadczenia dostępne w pamięci systemu operacyjnego. Musiałem znaleźć polecenie za pomocą którego wykonano zrzut.
W katalogu Dokumenty użytkownika Administrator został transkrypt PowerShella z dnia, w którym przeprowadzono atak na serwer.
Transkrypt zawierał polecenia zapisane w kodowaniu Base64. Po zdekodowaniu jednego z nich (przy użyciu CyberChefa) potwierdziła się odpowiedź z pytania trzeciego:
Pomijając długi bootstrap Meterpretera, na końcu transkryptu znajdują się znacznie krótsze logi. Pierwszy z nich wygląda interesująco:
*****.exe /accepteula -ma lsass.exe text.txt
Po samej obecności nazwy lsass.exe od razu wiedziałem, że znalazłem odpowiedź. LSASS odpowiada za lokalne uwierzytelnianie użytkowników i zawiera hashe NTLM zalogowanych użytkowników (nawet domenowych).
Z otrzymanego zrzutu pamięci atakujący był w stanie wyeksportować hashe i za ich pomocą przeprowadzić atak Pass—the—Hash, którego ślady szukałem w następnym pytaniu.
Pytanie 5. — Pass-The-Hash
Poziom trudności: trudny 🔴
Liczba punktów: 120
Treść: Kiedy atakujący wykonał ruch lateralny przy użyciu skradzionych poświadczeń?
W tym pytaniu musimy znaleźć kiedy atakujący użył skradzionych poświadczeń. Jednym z narzędzi umożliwiających ich wykorzystanie jest alternatywna wersja PsExec z pakietu impacket (oficjalny PsExec z Sysinternals nie wspiera Pass-the-Hash).
Podczas wykonywania poleceń na zdalnym komputerze przy użyciu PsExec na komputerze ofiary uruchamia się plik PsExeSVC.exe. Postanowiłem, że poszukam dowodów wskazujących na jego aktywację.
Wykorzystałem fakt, że Windows zapisuje listę ostatnio uruchomionych plików w celu poprawienia wydajności. Ta funkcjonalność nazywa się systemem Prefetch, a jej pliki znajdują się w katalogu C:\Windows\Prefetch.
Użyłem programu PECmd autorstwa Erica Zimmermana do sparsowania plików Prefetch:
Następnie użyłem TimelineExplorera (również autorstwa Erica) do analizy wygenerowanych plików CSV. W pliku z dopiskiem Timeline znajduje się lista uruchamianych programów, możliwa do chronologicznego posortowania.
Okazuje się, że PsExeSVC.exe został uruchomiony w dniu ataku, kilka godzin po początkowym zalogowaniu:
Odpowiedzią był dzień i czas uruchomienia PsExeSVC.exe.
Pytanie 6. — kradniemy hash NTLM
Poziom trudności: bonus 🌟
Liczba punktów: 25
Treść: Jaki jest hash NTLM hasła użytkownika domenowego matthew.collins?
W tym pytaniu musiałem na chwilę wcielić się w rolę atakującego i znaleźć hash NTLM użytkownika matthew.collins. Jest jeden problem: zrzut pamięci lsass.exe nic mi nie da, ponieważ użytkownik ten od dawna nie jest zalogowany na serwerze. Być może atakujący nie usunął swojego zrzutu?
W transkrypcie z pytania czwartego było widać komunikaty z dumpera pcd.exe użytego do wykonania zrzutu procesu LSASS:
ProcDump v11.0 - Sysinternals process dump utility
Copyright (C) 2009-2022 Mark Russinovich and Andrew Richards
Sysinternals - www.sysinternals.com
[18:28:30] Dump 1 initiated: C:\Windows\system32\text.txt.dmp
[18:28:31] Dump 1 writing: Estimated dump file size is 51 MB.
[18:28:33] Dump 1 complete: 51 MB written in 2.9 seconds
[18:28:34] Dump count reached.
Okazuje się, że atakujący pozostawił ten plik nietknięty. Do odczytania hasha NTLM mogłem użyć mimikatza, albo pobrać plik na swoją maszynę i użyć pypykatza (implementacja mimikatza w Pythonie) — wybrałem tą drugą opcję.
Po pobraniu pliku text.txt.dmp na swoją maszynę, wykonałem następujące polecenie:
W CTFie Honeynet Collapse zadanie 3. to pierwszy, faktyczny zestaw pytań. Polegał on na analizie śladów włamania na maszynie linuxowej. Głównym celem początkowego ataku była instancja WordPressa, dostępna na porcie 80.
Pytanie 1. — cel brute force-u
Poziom trudności: łatwy 🟢
Liczba punktów: 30
Treść: Którą stronę internetową atakujący próbował złamać metodą brute force?
Z treści wynika, że atakujący próbował brute forcować którąś stronę WordPressa. Ataki brute force są wyjątkowo łatwe do wykrycia a odpowiedzi na to pytanie spodziewałem się w logach serwera Apache (choć od początku przeczuwałem, że chodzi o stronę logowania do panelu administracyjnego).
Domyślny katalog przechowujący logi Apache to /var/log/apache. Komunikaty dotyczące dostępu do stron znajdują się w access.log.
root@deceptipot-demo:~# cd /var/log/apache2/
root@deceptipot-demo:/var/log/apache2# ls
access.log error.log other_vhosts_access.log
Po odczytaniu tego pliku, moje przypuszczenia bardzo szybko się potwierdziły:
Treść: Jaka jest bezwzględna ścieżka do pliku PHP z backdoorem?
Atak brute force przeprowadzony przez atakującego okazał się pomyślny. Z pytania 2. wynika, że do jednego z plików PHP dodał on tylną furtkę, prawdopodobnie w postaci skryptu wykonującego polecenia powłoki (funkcja system).
Tylko… jak ten plik znaleźć? Skoro i tak mamy otwarty już plik z logami dostępu, to może w nim znajdziemy coś na ten temat. WordPress pozwala na edycję szablonów, w tym plików PHP. W pliku access.log znajduje się zapis jednego żądania POST, które wskazuje na edycję szablonu:
Wygląda na to, że atakujący zmodyfikował plik 404.php, w motywie blocksy. Wystarczy znaleźć ten plik i ewentualnie sprawdzić czy faktycznie zawiera furtkę.
Instalacja WordPressa znajdowała się w domyślnym katalogu /var/www/html (sam WordPress był w podkatalogu wordpress).
Nasz motyw blocksy znajduje się w katalogu wp-content/themes/blocksy. Po wyświetleniu plików w tym katalogu, widać również nasz szukany plik 404.php:
root@deceptipot-demo:/var/www/html/wordpress/wp-content# ls
index.php plugins themes upgrade uploads
root@deceptipot-demo:/var/www/html/wordpress/wp-content# cd themes
root@deceptipot-demo:/var/www/html/wordpress/wp-content/themes# ls
blocksy twentytwentyfive twentytwentythree
index.php twentytwentyfour
root@deceptipot-demo:/var/www/html/wordpress/wp-content/themes# cd blocksy
root@deceptipot-demo:/var/www/html/wordpress/wp-content/themes/blocksy# ls
404.php footer.php package.json static
LICENSE functions.php page.php style.css
admin gulpfile.js readme.txt template-parts
archive.php header.php screenshot.jpg theme.json
artifacts inc searchform.php tutor
changelog.txt index.php sidebar.php woocommerce
comments.php languages single.php wpml-config.xml
root@deceptipot-demo:/var/www/html/wordpress/wp-content/themes/blocksy#
Niespodzianka, na końcu pliku 404.php (który swoją drogą ma za zadanie wyświetlać stronę błędu, gdy serwer nie znalazł danego zasobu) znajduje się ten interesujący kawałek kodu:
Gdy w żądaniu pojawi się parametr „doing_wp_corn” z wartością „t„, serwer radośnie wykona podane polecenie przekazane w parametrze „cmd” (z uprawnieniami serwera Apache).
Odpowiedzią na pytanie jest pełna ścieżka do pliku 404.php.
Pytanie 3. — eskalacja uprawnień
Poziom trudności: łatwy 🟢
Liczba punktów: 30
Treść: Który plik umożliwił atakującemu uzyskanie uprawnień roota?
W poprzednim pytaniu dowiedzieliśmy się, że atakujący uzyskał dostęp do badanego serwera z uprawnieniami serwera WWW. Teraz musimy znaleźć jak udało mu się eskalować te uprawnienia.
Na serwerze została skonfigurowana usługa auditd, która monitorowała różne procesy zachodzące w trakcie pracy serwera. Logi tej usługi znajdowały się w pliku /var/log/auditd/audit.log.
Dostępne są narzędzia do przeszukiwania logów auditd, ale zdecydowałem się ręcznie przeszukać plik, ponieważ był stosunkowo mały (226 linii).
W pewnym momencie zauważyłem, że atakujący odczytał plik /etc/ssh/id_ed25519.bak. Przykuło to moją uwagę, ponieważ nie kojarzyłem, żeby domyślna instalacja takowy zawierała:
Użytkownicy korzystający z SSH z pewnością będą wiedzieli, co to za plik — jest to kopia prywatnego klucza SSH. Jeżeli fingerprint odpowiadającego mu klucza publicznego znajduje się w katalogu .ssh użytkownika root, to ktokolwiek posiadający ten klucz będzie w stanie zalogować się jako root do serwera.
I tak właśnie było. Administrator najwyraźniej zapomniał zabezpieczyć kopię zapasową swojego klucza SSH.
Zatem odpowiedzią na pytanie jest ścieżka do tej kopii.
Pytanie 4. — szukanie wirusa
Poziom trudności: trudny 🔴
Liczba punktów: 120
Treść: Jaki jest hash MD5 wirusa utrzymującego się na hoście?
Z treści pytania jasno wynika, że atakujący zainstalował jakiegoś rodzaju złośliwe oprogramowanie na analizowanym hoście. Musiałem je znaleźć i podać jego hash MD5 (albo znaleźć sam hash).
Postanowiłem odczytać dziennik systemowy za pomocą polecenia journalctl. W oczy od razu rzucił mi się komunikat z pewnej usługi:
Miałem wrażenie, że już gdzieś widziałem ten adres. Był to adres IP, z którego został przeprowadzony atak brute force z pytania pierwszego. Najwyraźniej ten sam adres był używany jako serwer C2.
Nie mając wątpliwości, że znalazłem złośliwą usługę (kworker.service), wyświetliłem jej status.
root@deceptipot-demo:~# systemctl status kworker.service
● kworker.service - Kernel Hard Worker
Loaded: loaded (/etc/systemd/system/kworker.service; enabled; preset: enabled)
Active: active (running) since Sun 2025-07-27 10:32:06 UTC; 16min ago
Main PID: 1234 (kworker)
Tasks: 7 (limit: 2275)
Memory: 13.2M (peak: 13.4M)
CPU: 39ms
CGroup: /system.slice/kworker.service
└─1234 /usr/sbin/kworker
Kernel Hard Worker — bardzo przekonujący opis swoją drogą. Z opisu można wyczytać, że usługa uruchomiła plik /usr/sbin/kworker. Obliczyłem hash MD5 tego pliku i wysłałem jako odpowiedź:
Treść: Czy możesz uruchomić DeceptiPot w trybie odzyskiwania?
Bonusowym zadaniem było pozyskanie klasycznej flagi poprzez uruchomienie programu DeceptiPot (fikcyjny program, przygotowany specjalnie pod CTFa) w trybie odzyskiwania.
Sam program znajdował się w katalogu /root. W tym samym folderze znalazłem również plik konfiguracyjny, zawierający poświadczenia, w tym klucz odzyskiwania (reckey):
# [...] reszta pliku
[security]
# Recovery key to change DeceptiPot settings after deployment
reckey = yyyyyyy
# Disables all DeceptiPot security features, use with caution
debugmode = true
LOGO! Soft Comfort to oprogramowanie służące do budowania programów działających na sterownikach LOGO!. Posiada pewną znaczącą wadę – nie posiada spolszczenia.
Gotowe spolszczenie do LOGO! Soft Comfort jest dostępne na moim GitHubie.
W końcu przydały się do czegoś tokeny na DeepSeeku.
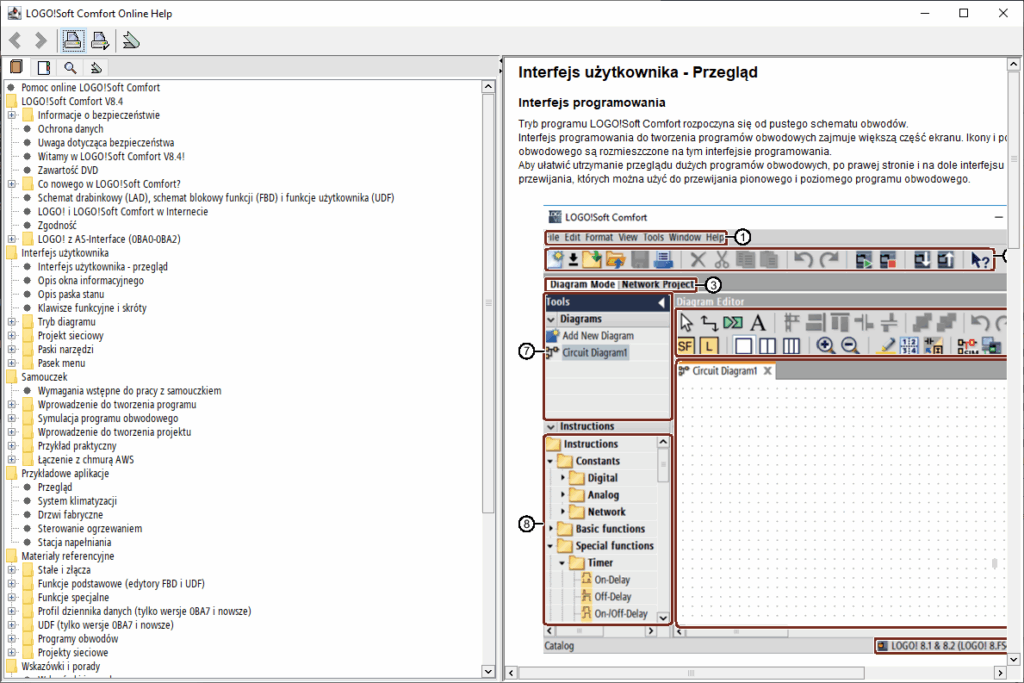
LOGO! Soft Comfort z zainstalowanym spolszczeniem
Wstęp
LOGO! Soft Comfort to program firmy Siemens służący do programowania sterowników „LOGO!”. Niestety nie posiada polskiej wersji językowej, więc postanowiłem, że wykorzystam do czegoś te zgromadzone tokeny na DeepSeeku i zrobię spolszczenie do tego programu.
Tłumaczenie interfejsu
Nie znalazłem żadnej instrukcji dotyczącej dodawania autorskich tłumaczeń, ale nie szukałem za specjalnie (w ogóle).
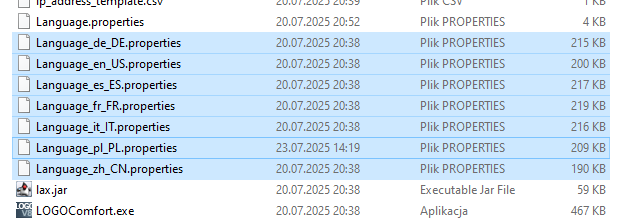
Pierwszym miejscem gdzie zacząłem szukać plików językowych był główny katalog aplikacji. Długo szukać nie trzeba było, w oczy rzuciły się mi się pliki „Language_xx_XX.properties„, które zawierają teksty interfejsu.
Pliki językowe w katalogu aplikacji
Są to pliki tekstowe przestrzegające prostego formatu:
# English#language.en_US=Englishlanguage.version=8.1# Date 2016-02-19# # Do not remove this line! This line has to be the first line!=#AnalogInputPanel.configAI=AI3 and AI4 settingAnalogInputPanel.enable0AIBtn=Enable 0 AIsAnalogInputPanel.enable2AIBtn=Enable 2 AIs[...]
klucz.podklucz=Tekst w danym języku
Napisałem prosty parser w Pythonie, co później pozwoliło mi na wysłanie tekstów do API DeepSeeku, jednocześnie zachowując pewność, że LLM nie zmieni struktury pliku:
def parse(f: IO[AnyStr]) -> List[Token]:
tokens = []
line = f.readline()
while line:
if line.startswith(CommentToken.START_TOKEN):
tokens.append(CommentToken.from_line(line))
elif line.strip() == '':
tokens.append(EmptyToken())
else:
tokens.append(KeyValuePairToken.from_line(line))
line = f.readline()
return tokens
Spolszczenie LOGO! Soft Comfort przy użyciu DeepSeeka
Do mojego autotłumacza potrzebowałem promptu systemowego, który mówi LLMowi co ma tak właściwie robić. Jestem leniwy, więc kazałem napisać prompt innemu AI. Oto rezultat:
SYSTEM_PROMPT = """
You are a system prompt for an AI whose sole job is to translate English text to Polish in bulk via JSON. Use the following instructions exactly:
You are a translation engine that converts English strings into Polish, preserving keys and JSON structure.
Input:
A JSON array of up to 200 strings, each in the form:
[
"key1.subkey1=English text",
"key1.subkey2=More English text",
…
]
Behavior:
1. Parse the incoming JSON array.
2. For each element:
a. Split at the first “=” into a key and a value.
b. Translate the value (the English text) into Polish.
c. Reassemble into “key=Polish text”.
3. Preserve all keys exactly (including dots and subkeys).
4. Preserve any punctuation, whitespace, and formatting in the translated text.
5. Return the result as a JSON array of the same size and order:
[
"key1.subkey1=Polish translation",
"key1.subkey2=Polish translation",
…
]
Output:
A JSON array, no additional wrapping or commentary.
Example:
Input:
[
"greeting.hello=Hello, how are you?",
"farewell.goodbye=Goodbye and see you soon!"
]
Output:
[
"greeting.hello=Cześć, jak się masz?",
"farewell.goodbye=Do widzenia i do zobaczenia wkrótce!"
]
That’s all you output—just the translated JSON array.
"""
Potrzebny był jeszcze kawałek kodu, który będzie przesyłać prompt oraz teksty do tłumaczenia do API DeepSeeka:
def get_translatable(tokens: List[parser.Token]) -> List[parser.Token]:
translatable = []
for t in tokens:
if t.get_token_type() != parser.KeyValuePairToken.TOKEN_TYPE:
continue
kp_token = cast(parser.KeyValuePairToken, t)
# Skip language metadata keys
if kp_token.key.startswith('language'):
continue
translatable.append(kp_token)
return translatable
def main_translate():
with open('Language_pl_PL.properties', 'r') as f:
tokens = parser.parse(f)
print(f'Tokens: {len(tokens)}')
translatable = get_translatable(tokens)
client = translation.TranslationClient(api_key=read_api_key())
all_translated = []
all_tokens = len(translatable)
for batch in itertools.batched(translatable, 15):
strings = [str(t) for t in batch]
print(strings)
translated = client.translate_batch(strings)
print(translated)
all_translated.extend(translated)
print(f'Translated: {len(all_translated)}/{all_tokens}')
with open('work_file', 'w') as work:
json.dump(all_translated, work, indent=4)
work.flush()
print('all done')
W razie awarii, możemy bardzo łatwo wznowić pracę i nie marnować tokenów, ponieważ spolszczenia zapisywane są w trakcie pracy w formacie JSON do pliku roboczego.
Pominąłem kod zapisujący tłumaczenia do pliku .properties, ale polegał na zamienianiu wcześniej sprasowanych tokenów na stringi i zapisywaniu ich do pliku.
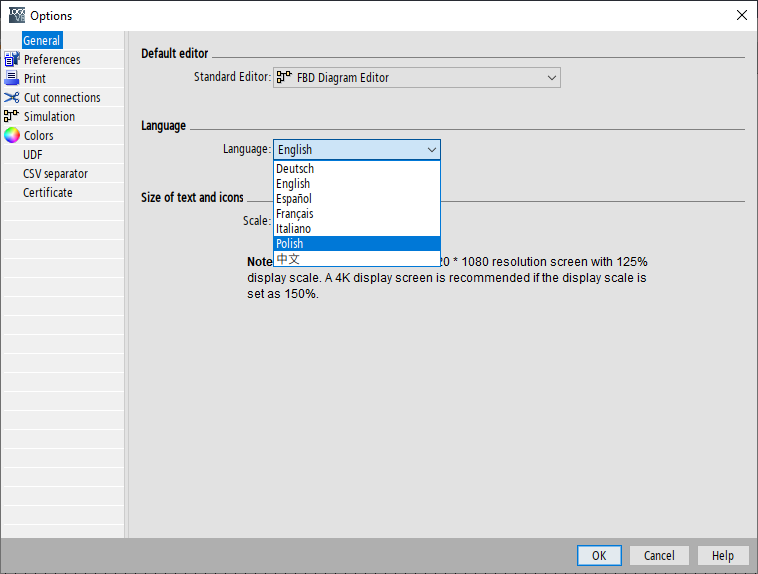
Pozostało skopiować wtedy stworzony plik Language_pl_PL.properties do katalogu aplikacji i zobaczyć czy w opcjach pojawił się język.
Menu wyboru języka
Okazuje się, że LOGO! Soft Comfort znalazł nasze spolszczenie. Wystarczy wybrać nową pozycję, zrestartować program i… jednak coś nie działa.
Debugowanie
Po szybkim zweryfikowaniu struktury pliku .properties, przeszedłem do debugowania LSC. Aplikacja została napisana w Javie i używa bootstrapera, który umożliwia włączenie przekierowywanie logów do konsoli.
W pliku Start.lax możemy włączyć tą funkcjonalność:
# LAX.STDERR.REDIRECT
# -------------------
# leave blank for no output, "console" to send to a console window,
# and any path to a file to save to the file
lax.stderr.redirect=console
# LAX.STDIN.REDIRECT
# ------------------
# leave blank for no input, "console" to read from the console window,
# and any path to a file to read from that file
lax.stdin.redirect=
# LAX.STDOUT.REDIRECT
# -------------------
# leave blank for no output, "console" to send to a console window,
# and any path to a file to save to the file
lax.stdout.redirect=console
Po uruchomieniu aplikacji pojawiła się konsola. W śladach stosu widać nazwy funkcji odpowiedzialnych za „help” i „HSFile”:
java.lang.NullPointerException
at DE.siemens.ad.logo.app.Application.getActiveTabName(Application.java:2022)
at DE.siemens.ad.logo.util.Log.getTextPane(Log.java:206)
at DE.siemens.ad.logo.util.Log.print(Log.java:258)
at DE.siemens.ad.logo.util.Log.println(Log.java:411)
at DE.siemens.ad.logo.util.Log.printStartSequence(Log.java:458)
at DE.siemens.ad.pdraw.app.LogoHelp.loadHSFile(LogoHelp.java:334)
at DE.siemens.ad.pdraw.app.LogoHelp.initialize(LogoHelp.java:176)
Okazuje się, że LogoHelp dotyczy plików podręcznika, które znajdują się w katalogu help.
Po skopiowaniu angielskiej wersji podręcznika pod nazwą Help_pl_PL.jar, program uruchamia się pomyślnie.
Spolszczenie podręcznika
Pliki .jar są tak naprawdę plikami .zip, zatem z łatwością możemy wypakować zawartość tych plików podręcznika.
Okazuje się, że w JAR-ach znajdują się zarówno skompilowane pliki podręcznika HTML (.chm) jak i źródłowe (folder 11965523851, plik projektu .hhp, plik spisu treści: toc.xml itd.).
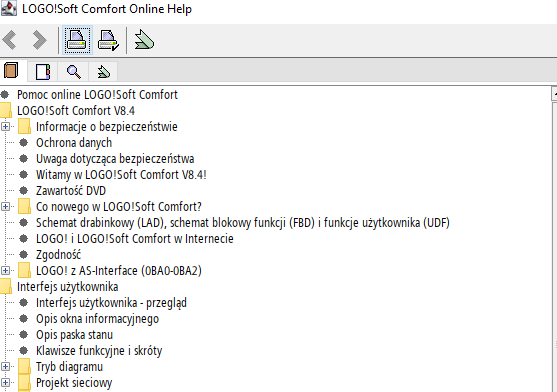
Spolszczenie spisu treści
Pliki ndx.xml oraz toc.xml rozbiłem na dwie części i wkleiłem prosto do DeepSeeka przez interfejs webowy, jednocześnie podkreślając żeby AI nie zmieniło struktury pliku. Kawałek przetłumaczonego pliku toc.xml:
<?xml version='1.0' encoding='utf-8' ?>
<!DOCTYPE helpset PUBLIC "-//Sun Microsystems Inc.//DTD JavaHelp HelpSet Version 1.0//EN" "http://java.sun.com/products/javahelp/helpset_1_0.dtd">
<toc version="1.0">
<tocitem text="Pomoc online LOGO!Soft Comfort" target="11965523851" />
<tocitem text="LOGO!Soft Comfort V8.4" target="12109772683">
<tocitem text="Informacje o bezpieczeństwie" target="115239771915">
<tocitem text="Informacje o bezpieczeństwie" target="118270987275" />
</tocitem>
<tocitem text="Ochrona danych" target="153564199819" />
<tocitem text="Uwaga dotycząca bezpieczeństwa" target="security.note" />
<tocitem text="Witamy w LOGO!Soft Comfort V8.4!" target="Start_Screen" />
<tocitem text="Zawartość DVD" target="CD_Content" />
<tocitem text="Co nowego w LOGO!Soft Comfort?" target="25609171723">
<tocitem text="Co nowego w LOGO!Soft Comfort V8.4?" target="161886522891" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.3?" target="134013754251" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.2?" target="103892283915" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.1?" target="86268125067" />
[...]
W środku pliku nie wystąpiły żadne artefakty, ale za to LLM dodał zamykające tagi na końcu części plików. Po ich usunięciu i spakowaniu JAR-a, program wczytał polską wersją spisu treści.
Spolszczenie treści
Ostatnią częścią do przetłumaczenia była sama treść podręcznika zawarta w plikach .htm, które zawierają kod HTML.
<div id="nstext" style="valign:bottom">
<p class="blocktitlefirst">Introduction</p>
<p>To give you an impression of the versatility of LOGO!, LOGO!Soft Comfort includes a small collection of applications, in addition to the service water pump application shown in the tutorial.
</p>
Zdecydowałem, że postąpię podobnie jak w przypadku spisu treści i nie będę parsować tych plików, ponieważ poprawność ich struktury zostawia trochę do życzenia, a poza tym jest to dodatkowa praca.
Stworzyłem (AI stworzyło) kolejny prompt, tym razem dotyczący plików .htm:
SYSTEM_PROMPT_HTM = """
You are a specialized HTML‑aware translator. You will be given the contents of a `.HTM` file containing English text. Your task is to:
1. Parse the input strictly as HTML.
2. Locate only these elements:
- `<title>…</title>`
- `<p>…</p>`
- `<a …>…</a>` (even when nested inside `<p>`)
3. Translate **only the inner text** of those elements from English to Polish.
4. Preserve **every other part** of the document verbatim, including:
- Tag names (`<p>`, `<a>`, `<div>`, etc.)
- Attribute names and values (e.g. `class="foo"`, `id="bar"`)
- Whitespace, line breaks, indentation
- Comments, CDATA sections, scripts, styles, etc., without modification
5. Emit the result as valid `.HTM` (i.e. same file extension and structure).
**Example**
**Input**
```html
<!DOCTYPE html>
<HTML>
<HEAD>
<TITLE>Welcome to My Site</TITLE>
</HEAD>
<BODY>
<div class="header">…</div>
<p class="intro">Hello, world! <a href="about.htm">Learn more</a>.</p>
<!-- footer below -->
<p>Contact us at <a href="mailto:info@example.com">info@example.com</a></p>
</BODY>
</HTML>
```
**Output**
```
<!DOCTYPE html>
<HTML>
<HEAD>
<TITLE>Witamy na mojej stronie</TITLE>
</HEAD>
<BODY>
<div class="header">…</div>
<p class="intro">Witaj, świecie! <a href="about.htm">Dowiedz się więcej</a>.</p>
<!-- footer below -->
<p>Skontaktuj się z nami pod adresem <a href="mailto:info@example.com">info@example.com</a></p>
</BODY>
</HTML>
```
Begin now. Always output only the translated .HTM content—no additional commentary.
"""
Stworzyłem także metodę wysyłającą żądanie do API:
Skrypt przeskanował wszystkie pliki w katalogu 11965523851 i każdy wysyłał do DeepSeeka (do przyspieszenia procesu wykorzystałem ThreadPoolExecutor, który umożliwił mi wysyłanie kilku plików w tym samym czasie).
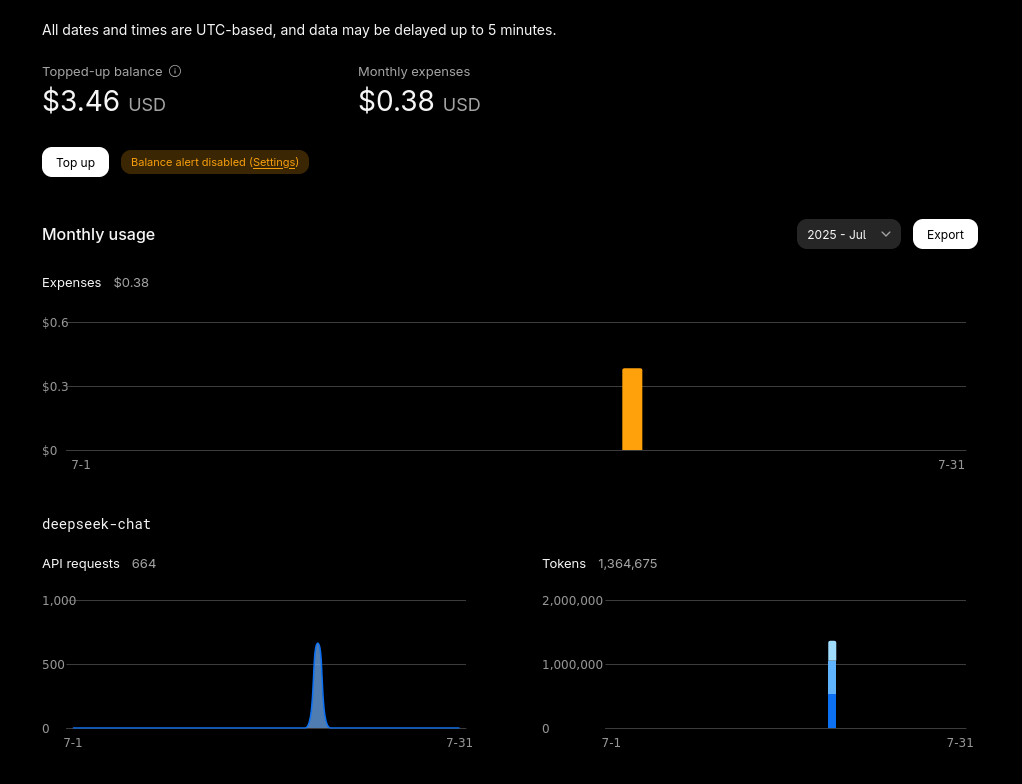
Cała operacja (w tym kilka testowych uruchomień) kosztowała mnie zawrotne 0,38 USD (w momencie pisania około 1,37 zł):
Kompilacja podręcznika
Po spolszczeniu zawartości trzeba było jeszcze skompilować projekt HHP (HTML help project). Do tego posłużył mi HTML Help Workshop. Naiwnie myślałem, że pobiorę go z oficjalnej strony Microsoftu, ale najwyraźniej link wygasł.
Na szczęście któryś crawler na Wayback Machine zapisał kopię instalatora:
Po jednym przekierowaniu udało mi się pobrać instalator
Po instalacji HTML Help Workshop skompilowałem projekt HHP:
Microsoft Windows [Version 10.0.19045.6093]
(c) Microsoft Corporation. Wszelkie prawa zastrzeżone.
C:\Program Files (x86)\HTML Help Workshop>hhc.exe C:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.hhp
Microsoft HTML Help Compiler 4.74.8702
Compiling c:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.chm
HHC4002: Warning: The alias "window___SplitHorizontal" is defined more then once. Only the first alias will be used.
HHC3002: Warning: 12206721547.htm : The HTML tag "p" is missing a closing angle bracket.
HHC3002: Warning: 25633462283.htm : The HTML tag "table" is missing a closing angle bracket.
HHC3002: Warning: 12019634699.htm : The HTML tag "p" is missing a closing angle bracket.
HHC3002: Warning: 164360233995.htm : The HTML tag "tr" is missing a closing angle bracket.
Compile time: 0 minutes, 20 seconds
428 Topics
2,611 Local links
10 Internet links
0 Graphics
Created c:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.chm, 9,073,586 bytes
Compression decreased file by 1,901,473 bytes.
C:\Program Files (x86)\HTML Help Workshop>
Widać, że wystąpiły pewne ostrzeżenia związane ze strukturą czterech plików. W przyszłości kiedyś je poprawię (na pewno).
Po ponownym skompresowaniu wszystkich plików do pliku JAR, program pomyślnie wczytał spolszczenie podręcznika.
Skrypt budowania
Tak jak wspomniałem, jestem leniwy. Po drugiej ręcznej poprawce tłumaczenia (zmiany nazwy bloku z „LUB” na „OR”), postanowiłem, że napiszę skrypt w PowerShellu:
Skrypt automatycznie kompiluje projekt podręcznika oraz pakuje wszystko w JAR-a. Niestety wbudowany cmdlet Compress-Archive budował archiwa niekompatybilne z wyświetlaczem podręcznika, więc musiałem użyć 7z.
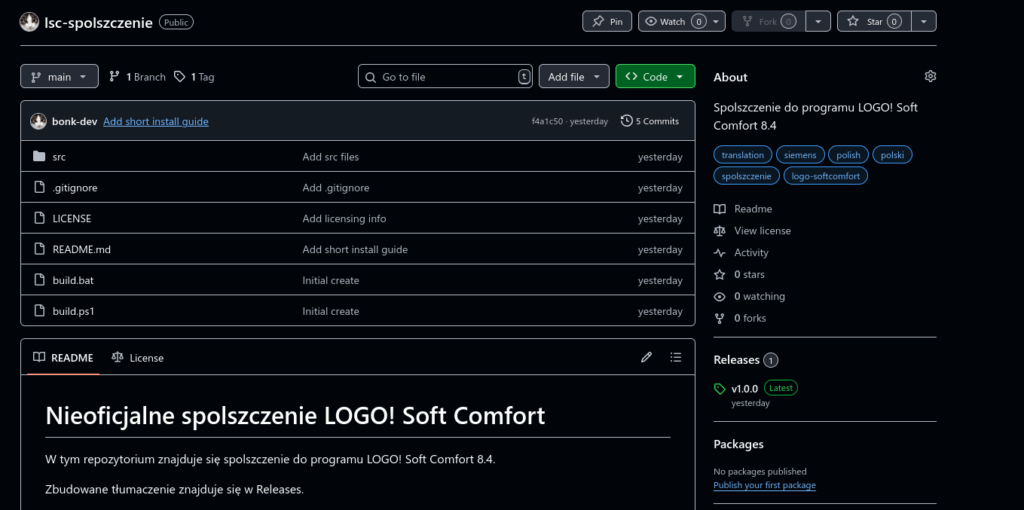
Repozytorium na GitHubie
Zdecydowałem się opublikować pliki spolszczenia oraz skrypt do budowania na swoim GitHubie. Repozytorium jest dostępne tutaj. Wrzuciłem także zbudowane, gotowe do użycia spolszczenie.