LOGO! Soft Comfort to oprogramowanie służące do budowania programów działających na sterownikach LOGO!. Posiada pewną znaczącą wadę – nie posiada spolszczenia.
Gotowe spolszczenie do LOGO! Soft Comfort jest dostępne na moim GitHubie.
W końcu przydały się do czegoś tokeny na DeepSeeku.
Wstęp
LOGO! Soft Comfort to program firmy Siemens służący do programowania sterowników „LOGO!”. Niestety nie posiada polskiej wersji językowej, więc postanowiłem, że wykorzystam do czegoś te zgromadzone tokeny na DeepSeeku i zrobię spolszczenie do tego programu.
Tłumaczenie interfejsu
Nie znalazłem żadnej instrukcji dotyczącej dodawania autorskich tłumaczeń, ale nie szukałem za specjalnie (w ogóle).
Pierwszym miejscem gdzie zacząłem szukać plików językowych był główny katalog aplikacji. Długo szukać nie trzeba było, w oczy rzuciły się mi się pliki „Language_xx_XX.properties„, które zawierają teksty interfejsu.
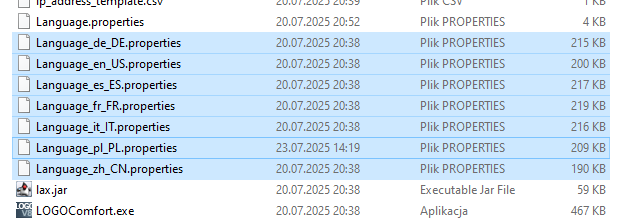
Są to pliki tekstowe przestrzegające prostego formatu:
# English
#
language.en_US=English
language.version=8.1
# Date 2016-02-19
#
# Do not remove this line! This line has to be the first line!=#
AnalogInputPanel.configAI=AI3 and AI4 setting
AnalogInputPanel.enable0AIBtn=Enable 0 AIs
AnalogInputPanel.enable2AIBtn=Enable 2 AIs
[...]klucz.podklucz=Tekst w danym językuNapisałem prosty parser w Pythonie, co później pozwoliło mi na wysłanie tekstów do API DeepSeeku, jednocześnie zachowując pewność, że LLM nie zmieni struktury pliku:
def parse(f: IO[AnyStr]) -> List[Token]:
tokens = []
line = f.readline()
while line:
if line.startswith(CommentToken.START_TOKEN):
tokens.append(CommentToken.from_line(line))
elif line.strip() == '':
tokens.append(EmptyToken())
else:
tokens.append(KeyValuePairToken.from_line(line))
line = f.readline()
return tokensSpolszczenie LOGO! Soft Comfort przy użyciu DeepSeeka
Do mojego autotłumacza potrzebowałem promptu systemowego, który mówi LLMowi co ma tak właściwie robić. Jestem leniwy, więc kazałem napisać prompt innemu AI. Oto rezultat:
SYSTEM_PROMPT = """
You are a system prompt for an AI whose sole job is to translate English text to Polish in bulk via JSON. Use the following instructions exactly:
You are a translation engine that converts English strings into Polish, preserving keys and JSON structure.
Input:
A JSON array of up to 200 strings, each in the form:
[
"key1.subkey1=English text",
"key1.subkey2=More English text",
…
]
Behavior:
1. Parse the incoming JSON array.
2. For each element:
a. Split at the first “=” into a key and a value.
b. Translate the value (the English text) into Polish.
c. Reassemble into “key=Polish text”.
3. Preserve all keys exactly (including dots and subkeys).
4. Preserve any punctuation, whitespace, and formatting in the translated text.
5. Return the result as a JSON array of the same size and order:
[
"key1.subkey1=Polish translation",
"key1.subkey2=Polish translation",
…
]
Output:
A JSON array, no additional wrapping or commentary.
Example:
Input:
[
"greeting.hello=Hello, how are you?",
"farewell.goodbye=Goodbye and see you soon!"
]
Output:
[
"greeting.hello=Cześć, jak się masz?",
"farewell.goodbye=Do widzenia i do zobaczenia wkrótce!"
]
That’s all you output—just the translated JSON array.
"""Potrzebny był jeszcze kawałek kodu, który będzie przesyłać prompt oraz teksty do tłumaczenia do API DeepSeeka:
from openai import OpenAI
SYSTEM_PROMPT = """[...]"""
class TranslationClient:
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com")
def translate_batch(self, texts: List[str]) -> List[str]:
response = self.client.chat.completions.create(
model='deepseek-chat',
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": json.dumps(texts)}
],
stream=False
)
return json.loads(response.choices[0].message.content)Pozostało tylko połączyć to wszystko w mainie:
def get_translatable(tokens: List[parser.Token]) -> List[parser.Token]:
translatable = []
for t in tokens:
if t.get_token_type() != parser.KeyValuePairToken.TOKEN_TYPE:
continue
kp_token = cast(parser.KeyValuePairToken, t)
# Skip language metadata keys
if kp_token.key.startswith('language'):
continue
translatable.append(kp_token)
return translatable
def main_translate():
with open('Language_pl_PL.properties', 'r') as f:
tokens = parser.parse(f)
print(f'Tokens: {len(tokens)}')
translatable = get_translatable(tokens)
client = translation.TranslationClient(api_key=read_api_key())
all_translated = []
all_tokens = len(translatable)
for batch in itertools.batched(translatable, 15):
strings = [str(t) for t in batch]
print(strings)
translated = client.translate_batch(strings)
print(translated)
all_translated.extend(translated)
print(f'Translated: {len(all_translated)}/{all_tokens}')
with open('work_file', 'w') as work:
json.dump(all_translated, work, indent=4)
work.flush()
print('all done')W razie awarii, możemy bardzo łatwo wznowić pracę i nie marnować tokenów, ponieważ spolszczenia zapisywane są w trakcie pracy w formacie JSON do pliku roboczego.
Pominąłem kod zapisujący tłumaczenia do pliku .properties, ale polegał na zamienianiu wcześniej sprasowanych tokenów na stringi i zapisywaniu ich do pliku.
Pozostało skopiować wtedy stworzony plik Language_pl_PL.properties do katalogu aplikacji i zobaczyć czy w opcjach pojawił się język.
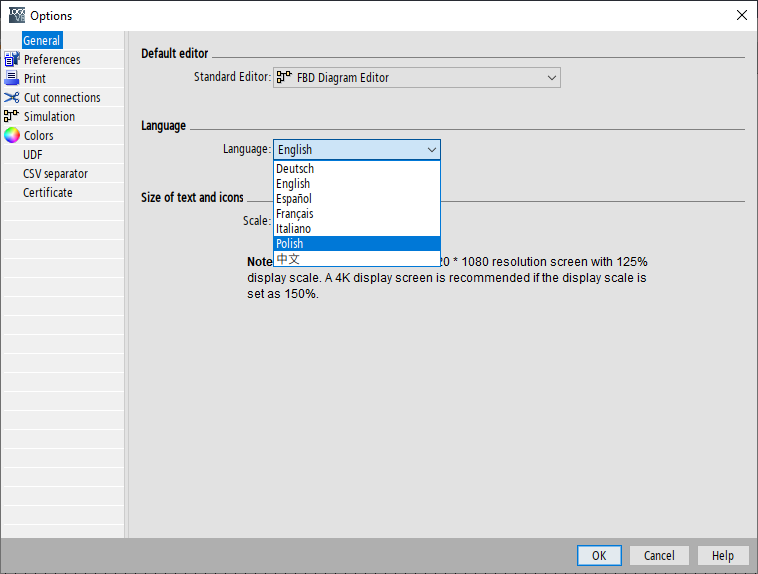
Okazuje się, że LOGO! Soft Comfort znalazł nasze spolszczenie. Wystarczy wybrać nową pozycję, zrestartować program i… jednak coś nie działa.
Debugowanie
Po szybkim zweryfikowaniu struktury pliku .properties, przeszedłem do debugowania LSC. Aplikacja została napisana w Javie i używa bootstrapera, który umożliwia włączenie przekierowywanie logów do konsoli.
W pliku Start.lax możemy włączyć tą funkcjonalność:
# LAX.STDERR.REDIRECT
# -------------------
# leave blank for no output, "console" to send to a console window,
# and any path to a file to save to the file
lax.stderr.redirect=console
# LAX.STDIN.REDIRECT
# ------------------
# leave blank for no input, "console" to read from the console window,
# and any path to a file to read from that file
lax.stdin.redirect=
# LAX.STDOUT.REDIRECT
# -------------------
# leave blank for no output, "console" to send to a console window,
# and any path to a file to save to the file
lax.stdout.redirect=consolePo uruchomieniu aplikacji pojawiła się konsola. W śladach stosu widać nazwy funkcji odpowiedzialnych za „help” i „HSFile”:
java.lang.NullPointerException
at DE.siemens.ad.logo.app.Application.getActiveTabName(Application.java:2022)
at DE.siemens.ad.logo.util.Log.getTextPane(Log.java:206)
at DE.siemens.ad.logo.util.Log.print(Log.java:258)
at DE.siemens.ad.logo.util.Log.println(Log.java:411)
at DE.siemens.ad.logo.util.Log.printStartSequence(Log.java:458)
at DE.siemens.ad.pdraw.app.LogoHelp.loadHSFile(LogoHelp.java:334)
at DE.siemens.ad.pdraw.app.LogoHelp.initialize(LogoHelp.java:176)Okazuje się, że LogoHelp dotyczy plików podręcznika, które znajdują się w katalogu help.
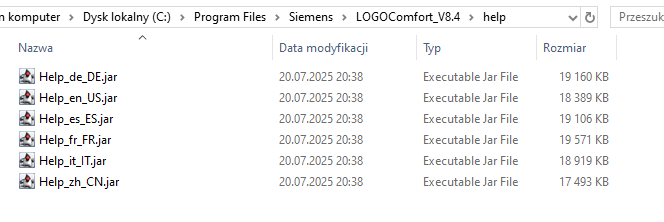
Po skopiowaniu angielskiej wersji podręcznika pod nazwą Help_pl_PL.jar, program uruchamia się pomyślnie.
Spolszczenie podręcznika
Pliki .jar są tak naprawdę plikami .zip, zatem z łatwością możemy wypakować zawartość tych plików podręcznika.
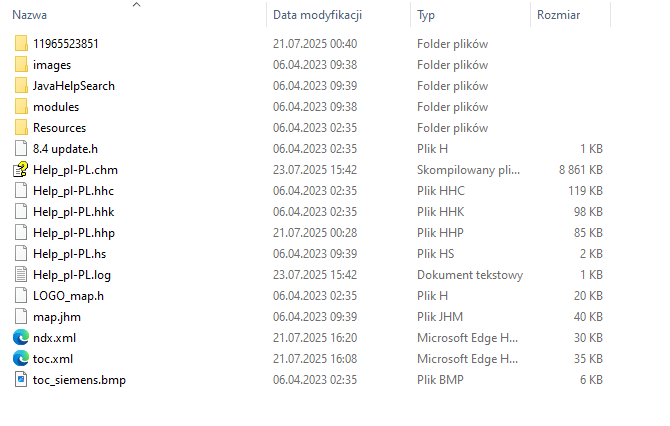
Okazuje się, że w JAR-ach znajdują się zarówno skompilowane pliki podręcznika HTML (.chm) jak i źródłowe (folder 11965523851, plik projektu .hhp, plik spisu treści: toc.xml itd.).
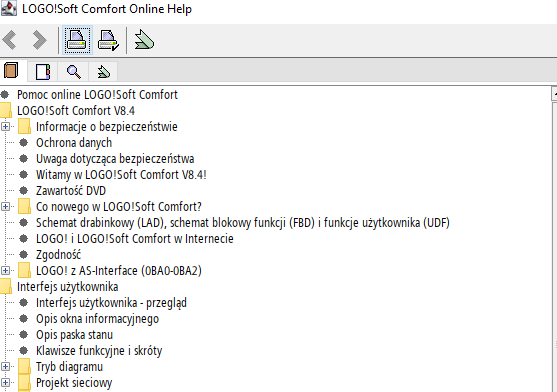
Spolszczenie spisu treści
Pliki ndx.xml oraz toc.xml rozbiłem na dwie części i wkleiłem prosto do DeepSeeka przez interfejs webowy, jednocześnie podkreślając żeby AI nie zmieniło struktury pliku. Kawałek przetłumaczonego pliku toc.xml:
<?xml version='1.0' encoding='utf-8' ?>
<!DOCTYPE helpset PUBLIC "-//Sun Microsystems Inc.//DTD JavaHelp HelpSet Version 1.0//EN" "http://java.sun.com/products/javahelp/helpset_1_0.dtd">
<toc version="1.0">
<tocitem text="Pomoc online LOGO!Soft Comfort" target="11965523851" />
<tocitem text="LOGO!Soft Comfort V8.4" target="12109772683">
<tocitem text="Informacje o bezpieczeństwie" target="115239771915">
<tocitem text="Informacje o bezpieczeństwie" target="118270987275" />
</tocitem>
<tocitem text="Ochrona danych" target="153564199819" />
<tocitem text="Uwaga dotycząca bezpieczeństwa" target="security.note" />
<tocitem text="Witamy w LOGO!Soft Comfort V8.4!" target="Start_Screen" />
<tocitem text="Zawartość DVD" target="CD_Content" />
<tocitem text="Co nowego w LOGO!Soft Comfort?" target="25609171723">
<tocitem text="Co nowego w LOGO!Soft Comfort V8.4?" target="161886522891" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.3?" target="134013754251" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.2?" target="103892283915" />
<tocitem text="Co nowego w LOGO!Soft Comfort V8.1?" target="86268125067" />
[...]W środku pliku nie wystąpiły żadne artefakty, ale za to LLM dodał zamykające tagi na końcu części plików. Po ich usunięciu i spakowaniu JAR-a, program wczytał polską wersją spisu treści.
Spolszczenie treści
Ostatnią częścią do przetłumaczenia była sama treść podręcznika zawarta w plikach .htm, które zawierają kod HTML.
<div id="nstext" style="valign:bottom">
<p class="blocktitlefirst">Introduction</p>
<p>To give you an impression of the versatility of LOGO!, LOGO!Soft Comfort includes a small collection of applications, in addition to the service water pump application shown in the tutorial.
</p>Zdecydowałem, że postąpię podobnie jak w przypadku spisu treści i nie będę parsować tych plików, ponieważ poprawność ich struktury zostawia trochę do życzenia, a poza tym jest to dodatkowa praca.
Stworzyłem (AI stworzyło) kolejny prompt, tym razem dotyczący plików .htm:
SYSTEM_PROMPT_HTM = """
You are a specialized HTML‑aware translator. You will be given the contents of a `.HTM` file containing English text. Your task is to:
1. Parse the input strictly as HTML.
2. Locate only these elements:
- `<title>…</title>`
- `<p>…</p>`
- `<a …>…</a>` (even when nested inside `<p>`)
3. Translate **only the inner text** of those elements from English to Polish.
4. Preserve **every other part** of the document verbatim, including:
- Tag names (`<p>`, `<a>`, `<div>`, etc.)
- Attribute names and values (e.g. `class="foo"`, `id="bar"`)
- Whitespace, line breaks, indentation
- Comments, CDATA sections, scripts, styles, etc., without modification
5. Emit the result as valid `.HTM` (i.e. same file extension and structure).
**Example**
**Input**
```html
<!DOCTYPE html>
<HTML>
<HEAD>
<TITLE>Welcome to My Site</TITLE>
</HEAD>
<BODY>
<div class="header">…</div>
<p class="intro">Hello, world! <a href="about.htm">Learn more</a>.</p>
<!-- footer below -->
<p>Contact us at <a href="mailto:info@example.com">info@example.com</a></p>
</BODY>
</HTML>
```
**Output**
```
<!DOCTYPE html>
<HTML>
<HEAD>
<TITLE>Witamy na mojej stronie</TITLE>
</HEAD>
<BODY>
<div class="header">…</div>
<p class="intro">Witaj, świecie! <a href="about.htm">Dowiedz się więcej</a>.</p>
<!-- footer below -->
<p>Skontaktuj się z nami pod adresem <a href="mailto:info@example.com">info@example.com</a></p>
</BODY>
</HTML>
```
Begin now. Always output only the translated .HTM content—no additional commentary.
"""Stworzyłem także metodę wysyłającą żądanie do API:
def translate_htm(self, htm_text: str) -> str:
response = self.client.chat.completions.create(
model='deepseek-chat',
messages=[
{"role": "system", "content": SYSTEM_PROMPT_HTM},
{"role": "user", "content": htm_text}
],
stream=False
)
return response.choices[0].message.contentSkrypt przeskanował wszystkie pliki w katalogu 11965523851 i każdy wysyłał do DeepSeeka (do przyspieszenia procesu wykorzystałem ThreadPoolExecutor, który umożliwił mi wysyłanie kilku plików w tym samym czasie).
Cała operacja (w tym kilka testowych uruchomień) kosztowała mnie zawrotne 0,38 USD (w momencie pisania około 1,37 zł):
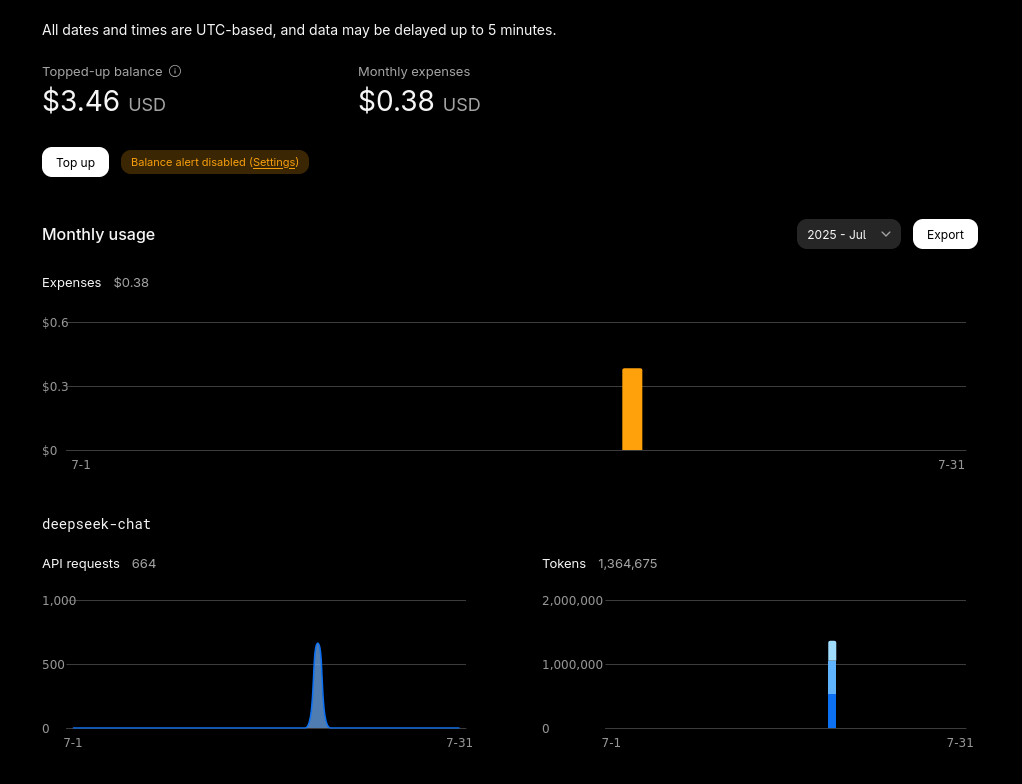
Kompilacja podręcznika
Po spolszczeniu zawartości trzeba było jeszcze skompilować projekt HHP (HTML help project). Do tego posłużył mi HTML Help Workshop. Naiwnie myślałem, że pobiorę go z oficjalnej strony Microsoftu, ale najwyraźniej link wygasł.

Na szczęście któryś crawler na Wayback Machine zapisał kopię instalatora:

Po jednym przekierowaniu udało mi się pobrać instalator

Po instalacji HTML Help Workshop skompilowałem projekt HHP:
Microsoft Windows [Version 10.0.19045.6093]
(c) Microsoft Corporation. Wszelkie prawa zastrzeżone.
C:\Program Files (x86)\HTML Help Workshop>hhc.exe C:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.hhp
Microsoft HTML Help Compiler 4.74.8702
Compiling c:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.chm
HHC4002: Warning: The alias "window___SplitHorizontal" is defined more then once. Only the first alias will be used.
HHC3002: Warning: 12206721547.htm : The HTML tag "p" is missing a closing angle bracket.
HHC3002: Warning: 25633462283.htm : The HTML tag "table" is missing a closing angle bracket.
HHC3002: Warning: 12019634699.htm : The HTML tag "p" is missing a closing angle bracket.
HHC3002: Warning: 164360233995.htm : The HTML tag "tr" is missing a closing angle bracket.
Compile time: 0 minutes, 20 seconds
428 Topics
2,611 Local links
10 Internet links
0 Graphics
Created c:\Users\bonk\Desktop\spolszczenie-logo-src\src\help\Help_pl-PL.chm, 9,073,586 bytes
Compression decreased file by 1,901,473 bytes.
C:\Program Files (x86)\HTML Help Workshop>Widać, że wystąpiły pewne ostrzeżenia związane ze strukturą czterech plików. W przyszłości kiedyś je poprawię (na pewno).
Po ponownym skompresowaniu wszystkich plików do pliku JAR, program pomyślnie wczytał spolszczenie podręcznika.
Skrypt budowania
Tak jak wspomniałem, jestem leniwy. Po drugiej ręcznej poprawce tłumaczenia (zmiany nazwy bloku z „LUB” na „OR”), postanowiłem, że napiszę skrypt w PowerShellu:
$hhc = "C:\Program Files (x86)\HTML Help Workshop\hhc.exe"
$zip = "C:\Program Files\7-Zip\7z.exe"
$version = "1.0.0"
$logoScVersion = "8.4"
$buildDir = ".\build"
$distDir = ".\dist"
$srcDir = ".\src"
if (Test-Path $buildDir) {
Remove-Item -Path $buildDir
}
New-Item -ItemType Directory -Force -Path $buildDir
New-Item -ItemType Directory -Force -Path $distDir
& $hhc "$srcDir\help\Help_pl-PL.hhp"
$buildArt = "$buildDir\Help_pl_PL.zip"
$compress = @{
Path = "$srcDir\help\*"
CompressionLevel = "Optimal"
DestinationPath = $buildArt
}
# Compress-Archive @compress
& $zip a $buildArt "$srcDir\help\*"
$buildDirDist = "$buildDir/dist"
New-Item -ItemType Directory -Path $buildDirDist
New-Item -ItemType Directory -Path "$buildDirDist\help"
Move-Item -Path $buildArt -Destination "$buildDirDist\help\Help_pl_PL.jar" -Force
Copy-Item -Path "$srcDir\Language_pl_PL.properties" -Destination "$buildDirDist\Language_pl_PL.properties"
Copy-Item -Path "$buildDirDist\*" -Destination "$distDir\" -Recurse -Force
$distZipName = "spolszczenie-$version-logo-$logoScVersion.zip"
$distZip = "$distDir\$distZipName"
if (Test-Path $distZip) {
Remove-Item -Path $distZip
}
$compress = @{
Path = $buildDirDist
CompressionLevel = "Optimal"
DestinationPath = $distZip
}
#Compress-Archive @compress
& $zip a $distZip $buildDirDist
Remove-Item -Path $buildDir -Recurse
Skrypt automatycznie kompiluje projekt podręcznika oraz pakuje wszystko w JAR-a. Niestety wbudowany cmdlet Compress-Archive budował archiwa niekompatybilne z wyświetlaczem podręcznika, więc musiałem użyć 7z.
Repozytorium na GitHubie
Zdecydowałem się opublikować pliki spolszczenia oraz skrypt do budowania na swoim GitHubie. Repozytorium jest dostępne tutaj. Wrzuciłem także zbudowane, gotowe do użycia spolszczenie.